Domain Name Encryption Is Not Enough: Privacy Leakage via IP-based Website Fingerprinting
Abstract
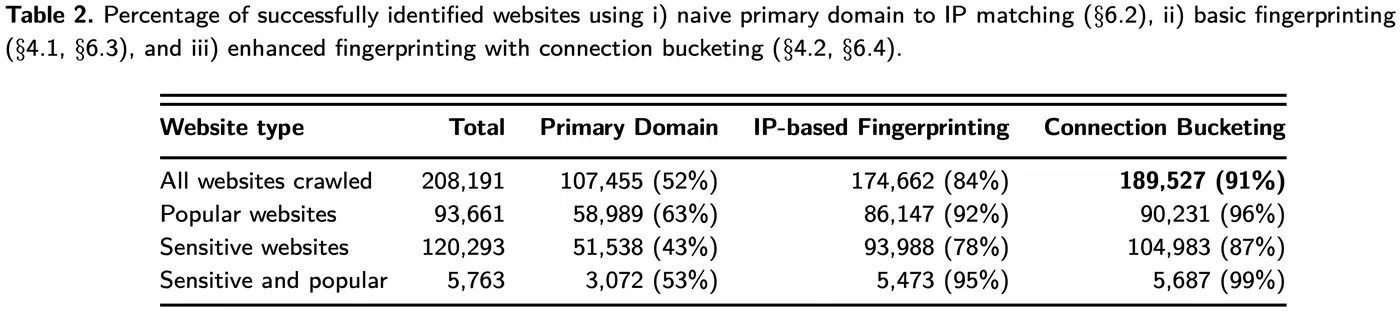
Although the security benefits of domain name encryption technologies such as DNS over TLS (DoT), DNS over HTTPS (DoH), and Encrypted Client Hello (ECH) are clear, their positive impact on user privacy is weakened by—the still exposed—IP address information. However, content delivery networks, DNS-based load balancing, co-hosting of different websites on the same server, and IP address churn, all contribute towards making domain–IP mappings unstable, and prevent straightforward IP-based browsing tracking. In this paper, we show that this instability is not a roadblock (assuming a universal DoT/DoH and ECH deployment), by introducing an IP-based website fingerprinting technique that allows a network-level observer to identify at scale the website a user visits. Our technique exploits the complex structure of most websites, which load resources from several domains besides their primary one. Using the generated fingerprints of more than 200K websites studied, we could successfully identify 84% of them when observing solely destination IP addresses. The accuracy rate increases to 92% for popular websites, and 95% for popular and sensitive websites. We also evaluated the robustness of the generated fingerprints over time, and demonstrate that they are still effective at successfully identifying about 70% of the tested websites after two months. We conclude by discussing strategies for website owners and hosting providers towards hindering IP-based website fingerprinting and maximizing the privacy benefits offered by DoT/DoH and ECH.This blog post describes the dataset used in our paper. A README.md file and
the dataset can be downloaded from this Google
Drive.
Please note that the size of the entire directory is about 59GB (compressed)
and would be more than 100GB when uncompressed.
0. Test Domains
Our list of test domains consists of 220,743 domains, including the top 100K popular domains of the Tranco list and 126,597 domains from Alexa’s sensitive categories. Among these, there are 5,854 common domains between the two data sources. The folder contains three files:
tranco.csv: the Tranco list was curated on March 3rd 2020.alexa.csv: 126,597 domains from the Alexa top site ranking are selected from categories often deemed as sensitive and censored around the globe.common.txt: 5,854 domains are common between the two data sources. In other words, these are popular and deemed sensitive domains.
1. Fingerprints
After visiting each website, we extract the queried domains to construct the website’s domain-based fingerprint. The corresponding IP-based fingerprint is then obtained by continuously resolving the domains into their IPs via active DNS measurement. In total, there are 24 crawl batches collected during the course of 2 months for this study. Of which, batch #1 is analyzed in §6 Fingerprinting Accuracy, whereas other batches are used for analyses in §7 Fingerprint Stability.
Each crawl batch folder contains a tarball domain_based.tar.gz, a
domains-ips.txt.gz mappings file, and a ip_based fingerprints folder.
1.1 Domain-based Fingerprint
The domain_based.tar.gz tarball in each crawl batch contains more than 200K
*.gz files, named after the domain of each website crawled. Each .gz file
has 3 lines. For example, the following 3 lines are from twitter.com.txt.gz
The first line is a list of tuples, containing relative times (starting from
0.0s) and domain names that were contacted when visitingtwitter.com[(0.0, 'twitter.com'), (0.984, 'abs.twimg.com'), (0.992, 'abs.twimg.com'), (0.996, 'abs.twimg.com'), (0.997, 'abs.twimg.com'), (0.998, 'abs.twimg.com'), (2.861, 'abs.twimg.com'), (2.862, 'abs.twimg.com'), (3.99, 'abs.twimg.com'), (3.991, 'abs.twimg.com'), (4.025, 'abs.twimg.com'), (4.032, 'abs.twimg.com'), (4.115, 'abs.twimg.com'), (4.137, 'abs.twimg.com'), (4.163, 'pbs.twimg.com'), (4.215, 'api.twitter.com'), (4.231, 'api.twitter.com'), (4.232, 'abs.twimg.com'), (4.67, 'api.twitter.com'), (4.677, 'api.twitter.com'), (5.648, 'api.twitter.com'), (6.47, 'twitter.com'), (6.981, 'api.twitter.com'), (7.018, 'api.twitter.com'), (7.268, 'www.google-analytics.com'), (8.609, 'www.google-analytics.com'), (8.691, 'api.twitter.com'), (9.223, 'abs.twimg.com'), (10.511, 'abs.twimg.com'), (10.512, 'abs.twimg.com')]The second line is the
basic domain-based fingerprintfortwitter.com. The construction of abasic domain-based fingerprintis described in §4.1.{0: {'twitter.com'}, 1: {'api.twitter.com', 'abs.twimg.com', 'pbs.twimg.com', 'www.google-analytics.com'}}The third line is the
enhanced domain-based fingerprintfortwitter.com. The construction of aenhanced domain-based fingerprintis described in §4.2.{0: {'twitter.com'}, 1: {'abs.twimg.com'}, 2: {'api.twitter.com', 'abs.twimg.com', 'pbs.twimg.com'}, 3: {'twitter.com', 'api.twitter.com', 'abs.twimg.com', 'www.google-analytics.com'}}
1.2 Domain-IP Mapping
Once extracted, all domains are then repeatedly resolved into their hosting IP
address(es). The file domains_ips.txt.gz contains domains contacted in each
crawl batch and their corresponding servers’ IP address(es), stored as
integers. For instance:
twitter.com;{1760832065, 1760832129, 1760832193, 1760832001}
abs.twimg.com;{2540008607, 3353879711, 2540030111, 2540032159, 1209359174, 3236277520, 2540042399}
1.3 IP-based Fingerprint
IP-based fingerprints are constructed from the domain-based fingerprints and
domain-IP mappings. There are two files of IP-based fingerprints, containing
basic and enhanced fingerprints. Note that IP addresses are presented as
integers.
Each line in the
basicfile contain the domain name of the website, followed by the website’sbasic IP-based fingerprint. The construction of abasic IP-based fingerprintis described in §4.1. The following example if thebasic IP-based fingerprintoftwitter.comtwitter.com;[1760832001, 1760832065, 1760832129, 1760832193];[385967085, 385968877, 1209359174, 1760832002, 1760832066, 1760832130, 1760832194, 2540008607, 2540030111, 2540032159, 2540042399, 2899903342, 2899904206, 2899904238, 2899904270, 2899905006, 2899905038, 2899905070, 2899905102, 2899905134, 2899905166, 2899905262, 2899905294, 2899905326, 2899905678, 2899905710, 2899905742, 3089042157, 3236277520, 3353879711, 3353886879]Each line in the
enhancedfile contain the domain name of the website, followed by the website’senhanced IP-based fingerprint. The construction of aenhanced IP-based fingerprintis described in §4.2. The following example if theenhanced IP-based fingerprintoftwitter.comtwitter.com;[1760832001, 1760832065, 1760832129, 1760832193];[1209359174, 2540008607, 2540030111, 2540032159, 2540042399, 3236277520, 3353879711];[385967085, 385968877, 1209359174, 1760832002, 1760832066, 1760832130, 1760832194, 2540008607, 2540030111, 2540032159, 2540042399, 3089042157, 3236277520, 3353879711, 3353886879];[1209359174, 1760832001, 1760832002, 1760832065, 1760832066, 1760832129, 1760832130, 1760832193, 1760832194, 2540008607, 2540030111, 2540032159, 2540042399, 2899903342, 2899904206, 2899904238, 2899904270, 2899905006, 2899905038, 2899905070, 2899905102, 2899905134, 2899905166, 2899905262, 2899905294, 2899905326, 2899905678, 2899905710, 2899905742, 3236277520, 3353879711]
2. Entropy
This folder contains information entropy values for each domain and ip,
described in §6.1 Fingerprint Entropy. There are approximately 475K unique
domains and 340K IP addresses observed per crawl batch. The following lines
are sample information entropy values of twitter.com and its hosting IP
addresses observed in batch #1.
twitter.com;11.112959325709589
1760832001;3.347563437887102
1760832065;3.347563437887102
1760832129;3.347563437887102
1760832193;3.347563437887102
3. Network Traces
Since there are 24 crawl batches as discussed earlier, there are also 24
tarballs containing these crawls’ network traces under network_traces. Each
tarball ([1-24].tar.gz) contains more than 200K traces. Each trace file,
named as {website}.txt.gz, has 3 lines. For example, the following 3 lines
are from twitter.com.txt.gz
The first line is a list of tuples, containing relative times (starting from
0.0s) and remote IP addresses of connections initiated when visitingtwitter.com[(0.0, 1760832065), (0.984, 1209359174), (0.992, 1209359174), (0.996, 1209359174), (0.997, 1209359174), (0.998, 1209359174), (2.861, 1209359174), (2.862, 1209359174), (3.99, 1209359174), (3.991, 1209359174), (4.025, 1209359174), (4.032, 1209359174), (4.115, 1209359174), (4.137, 1209359174), (4.163, 1209359174), (4.215, 1760832002), (4.231, 1760832002), (4.232, 1209359174), (4.67, 1760832002), (4.677, 1760832002), (5.648, 1760832002), (6.47, 1760832065), (6.981, 1760832002), (7.018, 1760832002), (7.268, 2899904270), (8.609, 2899904270), (8.691, 1760832002), (9.223, 1209359174), (10.511, 1209359174), (10.512, 1209359174)]The second line is the
basic IP-based fingerprintfortwitter.com, formatted as a dictionary. The construction of abasic IP-based fingerprintis described in §4.1.{0: {1760832065}, 1: {1760832065, 1760832002, 1209359174, 2899904270}}The third line is the
enhanced IP-based fingerprintfortwitter.com, formatted as a dictionary. The construction of aenhanced IP-based fingerprintis described in §4.2.{0: {1760832065}, 1: {1209359174}, 2: {1760832002, 1209359174}, 3: {1760832065, 1760832002, 1209359174, 2899904270}}
4. Cache
The tarball cache.tar.gz contains the time-to-live (ttl) values (in
seconds) for web resources fetched when visiting each website. For instance,
the file twitter.com.txt has the following lines:
twitter.com;[-1];-1
abs.twimg.com;[31535999, 31536000];31535999
pbs.twimg.com;[604800];604800
api.twitter.com;[-1, 0];-1
www.google-analytics.com;[-1, 6946];-1
Each line has three values separated by ; delimiter. The first value is a
domain from which web resource(s) are fetched. The second value is a sorted
list of ttl values (i.e., the freshness timeline) of web resources fetched
from that domain. The last value is the smallest ttl of the sorted list.
-1 denotes uncachable web resources while 0 indicates cacheable resources
but always need to be revalidated with their origin. In other words, these two
types of resources will always cause a network connection to their original
servers if revisited. Data in this folder is used for the analysis in §8.1
Impact of HTTP Caching on Website Fingerprinting Accuracy.
5. Brave
During the last four batches (from #21 to #24) of our data collection
process (i.e., ten days), at the same time with crawling the test websites
(without blocking ads and trackers), we instrumented the Brave browser to
crawl these websites a second time. While the Brave browser is loading each
website, we also capture (1) the set of contacted domains to fetch web
resources for rendering the website, and (2) the sequence of IPs contacted
(network traces).
Under each crawl batch folder, the contacted_domains.tar.gz tarball contains
more than 200K *.gz files, named after the domain of each website crawled.
Each .gz file stores a list of tuples, containing relative times (starting
from 0.0s) and domain names that were contacted when visiting with Brave.
For instance, bbc.com.txt.gz
[(0.0, 'bbc.com'), (0.124, 'bbc.com'), (0.489, 'www.bbc.com'), (1.859, 'nav.files.bbci.co.uk'), (1.945, 'nav.files.bbci.co.uk'), (1.946, 'nav.files.bbci.co.uk'), (1.946, 'nav.files.bbci.co.uk'), (1.978, 'static.files.bbci.co.uk'), (1.978, 'nav.files.bbci.co.uk'), (1.979, 'mybbc-analytics.files.bbci.co.uk'), (1.98, 'static.bbci.co.uk'), (1.98, 'static.bbci.co.uk'), (5.694, 'ichef.bbc.co.uk'), (18.699, 'ichef.bbc.co.uk'), (18.849, 'ichef.bbc.co.uk'), (19.018, 'ichef.bbc.co.uk'), (19.021, 'ichef.bbc.co.uk'), (19.032, 'static.bbci.co.uk'), (19.034, 'static.bbci.co.uk'), (19.034, 'ichef.bbc.co.uk'), (19.034, 'ichef.bbc.co.uk'), (19.035, 'ichef.bbc.co.uk'), (19.035, 'ichef.bbc.co.uk'), (19.102, 'ichef.bbc.co.uk'), (18.695, 'nav.files.bbci.co.uk'), (19.036, 'nav.files.bbci.co.uk'), (19.036, 'nav.files.bbci.co.uk'), (18.711, 'nav.files.bbci.co.uk'), (18.712, 'nav.files.bbci.co.uk'), (18.697, 'fig.bbc.co.uk'), (19.038, 'fig.bbc.co.uk'), (19.062, 'nav.files.bbci.co.uk'), (19.08, 'static.files.bbci.co.uk'), (19.084, 'nav.files.bbci.co.uk'), (19.085, 'nav.files.bbci.co.uk'), (19.101, 'nav.files.bbci.co.uk'), (19.113, 'static.bbci.co.uk'), (19.116, 'static.bbci.co.uk'), (19.256, 'static.files.bbci.co.uk'), (19.434, 'static.bbci.co.uk'), (19.59, 'nav.files.bbci.co.uk'), (19.722, 'idcta.api.bbc.co.uk'), (19.725, 'idcta.api.bbc.co.uk'), (20.43, 'www.bbc.com'), (20.492, 'mybbc.files.bbci.co.uk'), (20.494, 'static.files.bbci.co.uk'), (20.514, 'static.bbci.co.uk'), (20.927, 'emp.bbci.co.uk'), (20.954, 'ichef.bbc.co.uk'), (20.954, 'ichef.bbc.co.uk'), (20.955, 'ichef.bbc.co.uk'), (20.956, 'ichef.bbc.co.uk'), (20.956, 'ichef.bbc.co.uk'), (20.956, 'ichef.bbc.co.uk'), (21.04, 'ichef.bbc.co.uk'), (21.048, 'ichef.bbc.co.uk'), (21.048, 'ichef.bbc.co.uk'), (21.052, 'ichef.bbc.co.uk'), (21.092, 'ichef.bbc.co.uk'), (21.092, 'ichef.bbc.co.uk'), (21.123, 'ichef.bbc.co.uk'), (21.127, 'ichef.bbc.co.uk'), (20.964, 'ychef.files.bbci.co.uk'), (20.965, 'ychef.files.bbci.co.uk'), (20.965, 'ychef.files.bbci.co.uk'), (21.03, 'ychef.files.bbci.co.uk'), (21.168, 'ichef.bbc.co.uk'), (21.373, 'static.bbc.co.uk'), (21.375, 'static.bbc.co.uk'), (22.058, 'emp.bbc.com'), (34.88, 'gel.files.bbci.co.uk'), (22.66, 'emp.bbc.com'), (34.804, 'emp.bbc.com'), (34.995, 'www.bbc.com')]
In total, this list contains 15 unique domain names below.
{'static.bbc.co.uk', 'fig.bbc.co.uk', 'idcta.api.bbc.co.uk', 'mybbc-analytics.files.bbci.co.uk', 'ichef.bbc.co.uk', 'www.bbc.com', 'static.bbci.co.uk', 'emp.bbci.co.uk', 'nav.files.bbci.co.uk', 'emp.bbc.com', 'bbc.com', 'ychef.files.bbci.co.uk', 'mybbc.files.bbci.co.uk', 'static.files.bbci.co.uk', 'gel.files.bbci.co.uk'}
In contrast, there are 45 domain names contacted when visiting the same
website without ad blocking, which can be checked from this file
~/fingerprints/21/domain_based/bbc.com.txt.gz.
{'static.bbc.co.uk', 'fig.bbc.co.uk', 'tpc.googlesyndication.com', 'a4621041136.cdn.optimizely.com', 'r.bbci.co.uk', 'www.bbc.com', 'static.bbci.co.uk', 'bbc.com', 'a1.api.bbc.co.uk', 'tags.crwdcntrl.net', 'static.chartbeat.com', 'edigitalsurvey.com', 'detect-survey.effectivemeasure.net', 'static.files.bbci.co.uk', 't.effectivemeasure.net', 'adservice.google.com', 'ichef.bbc.co.uk', 'emp.bbc.com', 'cdn.optimizely.com', 'ssc.api.bbc.com', 'emp.bbci.co.uk', 'nav.files.bbci.co.uk', 'sb.scorecardresearch.com', 'www.googletagservices.com', 'bbc.gscontxt.net', 'secure-us.imrworldwide.com', 'mybbc.files.bbci.co.uk', 'bcp.crwdcntrl.net', 'imasdk.googleapis.com', 'idcta.api.bbc.co.uk', 'mybbc-analytics.files.bbci.co.uk', 'dt.adsafeprotected.com', 'ad.crwdcntrl.net', 'collector.effectivemeasure.net', 'ychef.files.bbci.co.uk', 'securepubads.g.doubleclick.net', 'survey.effectivemeasure.net', 'pixel.adsafeprotected.com', 'pagead2.googlesyndication.com', 'me-ssl.effectivemeasure.net', 'ping.chartbeat.net', 'privacy.crwdcntrl.net', 's0.2mdn.net', 'logx.optimizely.com', 'gel.files.bbci.co.uk'}
Each crawl batch folder also has a network_traces.tar.gz tarball, containing
more than 200K traces. Each trace file, named as {website}.txt.gz, has the
same format with network traces described above in Section 3. Network
Traces.