Augmenting Rule-based DNS Censorship Detection at Scale with Machine Learning
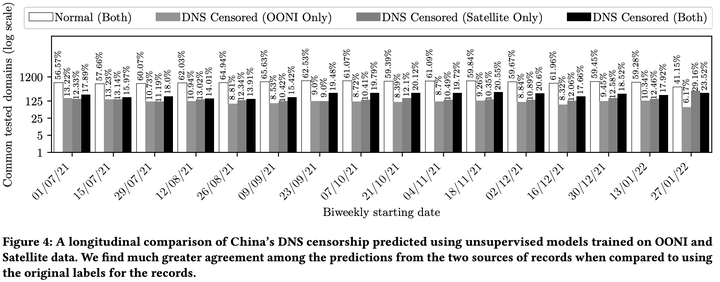 A longitudinal comparison of China’s DNS censorship predicted using unsupervised models
A longitudinal comparison of China’s DNS censorship predicted using unsupervised models
Abstract:
The proliferation of global censorship has led to the development of a plethora of measurement platforms to monitor and expose it. Censorship of the domain name system (DNS) is a key mechanism used across different countries. It is currently detected by applying heuristics to samples of DNS queries and responses (probes) for specific destinations. These heuristics, however, are both platform-specific and have been found to be brittle when censors change their blocking behavior, necessitating a more reliable automated process for detecting censorship.
In this paper, we explore how machine learning (ML) models can (1) help streamline the detection process, (2) improve the usability of large-scale datasets for censorship detection, and (3) discover new censorship instances and blocking signatures missed by existing heuristic methods. Our study shows that supervised models, trained using expert-derived labels on instances of known anomalies and possible censorship, can learn the detection heuristics employed by different measurement platforms. More crucially, we find that unsupervised models, trained solely on uncensored instances, can identify new instances and variations of censorship missed by existing heuristics. Moreover, both methods demonstrate the capability to uncover a substantial number of new DNS blocking signatures, i.e., injected fake IP addresses overlooked by existing heuristics. These results are underpinned by an important methodological finding: comparing the outputs of models trained using the same probes but with labels arising from independent processes allows us to more reliably detect cases of censorship in the absence of ground-truth labels of censorship.